




To demonstrate the difference between concurrency and parallelism, see the picture below.
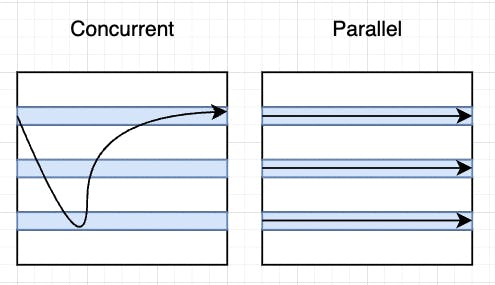 So on the left and on the right we have two diagrams that look the same.
One is labeled concurrency, the other is labelled parallelism. The three light blue bars represent tasks that the application can be working on.
So on the left and on the right we have two diagrams that look the same.
One is labeled concurrency, the other is labelled parallelism. The three light blue bars represent tasks that the application can be working on.
In a concurrent execution model, assuming that we have only one worker, then we have to work on one task at a time. Now we can switch between those tasks, but we can only ever be working on a single task at a time.
With parallelism, we can have multiple workers. So in that scenario we can actually act on all three tasks at the same time. So again, concurrency is multiple things that need to be done. Parallelism is the ability to work on those multiple tasks at the same time.
So lets see our .go file which contains the following
package main
import "fmt"
type Task struct {
ID int
Title string
Description string
Priority string
}
func (t Task) String() string {
return fmt.Sprintf(
"Title:\t\t%q\n"+
"Desc:\t\t%q\n"+
"Priority:\t%v\n", t.Title, t.Description, t.Priority)
}
var tasks = []Task{
Task{
ID: 1,
Title: "Task 1",
Description: "Task 1 description",
Priority: "Low",
},
Task{
ID: 2,
Title: "Task 2",
Description: "Task 2 description",
Priority: "High",
},
Task{
ID: 3,
Title: "Task 3",
Description: "Task 3 description",
Priority: "Medium",
},
Task{
ID: 4,
Title: "Task 4",
Description: "Task 4 description",
Priority: "Low",
},
Task{
ID: 5,
Title: "Task 5",
Description: "Task 5 description",
Priority: "Low",
},
Task{
ID: 6,
Title: "Task 6",
Description: "Task 6 description",
Priority: "Low",
},
Task{
ID: 7,
Title: "Task 7",
Description: "Task 7 description",
Priority: "High",
},
Task{
ID: 8,
Title: "Task 8",
Description: "Task 8 description",
Priority: "Low",
},
Task{
ID: 9,
Title: "Task 9",
Description: "Task 9 description",
Priority: "High",
},
Task{
ID: 10,
Title: "Task 10",
Description: "Task 10 description",
Priority: "Low",
},
}
We have a Task struct here and some tasks. We got a string method associated with that task, so we get back a nice formatted output when we print this out.
What we are going to be trying to do is to build a simulation for a database query system that also has an in-memory cache in front of it. So we are not going to be wiring up to a full database here. We are going to simulate that, and we are also going to simulate the in-memory cache. Now our goal is to be able to concurrently query the in-memory cache and the database and whichever one returns its entry first, we are going to use that result. So in the example that we have a hit on the cache, that is going to return almost instantaneously. However if we do not have a hit in the cache, we are going to query our database, which is a longer, slower operation.
Now let's use the following code in our main.go
package main
import (
"fmt"
"math/rand"
"time"
)
var cache = map[int]Task{}
var rnd = rand.New(rand.NewSource(time.Now().UnixNano()))
func main() {
for i := 0; i < 5; i++ {
id := rnd.Intn(5) + 1
fmt.Println("az id")
fmt.Println(id)
if t, ok := queryCache(id); ok {
fmt.Println("from cache")
fmt.Println(t)
continue
}
if t, ok := queryDatabase(id); ok {
fmt.Println("from database")
cache[id] = t
fmt.Println(t)
continue
}
fmt.Printf("Task not found id: '%v'", id)
time.Sleep(150 * time.Millisecond)
}
}
func queryCache(id int) (Task, bool) {
t, ok := cache[id]
return t, ok
}
func queryDatabase(id int) (Task, bool) {
time.Sleep(300 * time.Millisecond)
for _, t := range tasks {
if t.ID == id {
cache[id] = t
return t, true
}
}
return Task{}, false
}
What happens in the code above is that we generate random numbers. Then we query the cache and if this value is not available for us yet, we query the database, and also save the value in the cache. The next time the same value occurs, we can get it from to cache, which happens immediately - and much faster than if we would query it from the DB.
from database
Title: "Task 4"
Desc: "Task 4 description"
Priority:
from database
Title: "Task 3"
Desc: "Task 3 description"
Priority: "Medium"
from database
Title: "Task 1"
Desc: "Task 1 description"
Priority: "Low"
from cache
Title: "Task 1"
Desc: "Task 1 description"
Priority: "Low"
from cache
Title: "Task 3"
Desc: "Task 3 description"
Priority: "Medium"
So this code was a little demo. The next thing I want to do is to add some concurrency in here. But before we do that, let's talk about go routines and how they relate to operating system threads, another primary concurrent construct that you may have been used in the past.
Go routines
Now since go routines are very important part of Go programming language, let's mention some sentence about it .
If you worked in another programming languages, you may have heard about threads. A thread represents the ability for the operating system to run a task. So typical operating systems can often have thousands of threads active at a single time. Each one of those threads represents something that the operating system can be working on. It not always working on so many things at the single time, but it can. So this is similar to go routines, however not the same
Threads:
- Have own execution stack: there is a list of instructions that are assigned to that thread, and that thread starts working on it. So it has got its own memory and it has its own call stack, so it knows, what it is doing as it is doing it.
- Fixed stack space (around 1MB) - it is fixed by the operating system. This means that they have got a lot of room to do local operations, and if they need to do very large operations, they take advantage of the larger memory space called the heap space in order to manage that.
- Managed directly by the OS - your programming language requests the thread from the operating system
Goroutine:
- Have own execution stack
- Has a variable stack space that starts right around 2KB. So it is much much smaller, but if they do need to grow, the goroutine has the ability to increase its stack space to take on more and more local operations as needed. So generally they are much more efficient than threads, however they do have a little bit of overhead associated with them as they have to manage that stack space.
- Go routines and are managed by the Go runtime. Go is no different than other programming languages. It has threads as well, but they are managed by Go. So as you create goroutines, the Go runtime is going to manage mapping those goroutines onto the operating system threads for you. What this allows you to do in your typical Go application is create many, many more times the goroutines than the actual threads are operating. So a normal Go application can run easily hundreds or thousands of Go routines at the same time. Now this does not mean that there are hundreds of thousands of threads, your computer probably does not have enough memory to run that. However, the runtime provides an interface, allowing a relatively small number of threads to work with all of those go routines, and then the runtime schedules those goroutines onto the threads as things has to do.
The fact that goroutines are independent means that they do not have any built-in mechanism to allow them to coordinate them with one another.
There are two real challenges that we have to face when we are talking about concurrency, the first is how get things that will run concurrently - by goroutines, and the other is memory handling.
Now if we have concurrency, how do we get our concurrent tasks to coordinate with each other and share memory?
Coordinating tasks can be solved with WaitGroups
Shared memory can be handled by something called Mutexes. Mutexes are allowing us to protect memory that is shared between multiple goroutines to ensure that we have control over what is accessing that shared memory at a given time.
Sync package
There are two primary resources that you are going to use when you are trying to coordinate goroutines together.
The first is sync package and the other is channels.
sync.WaitGroup
the first member of the sync package that I want to talk about is the WaitGroup.
So what is a waitGroup? A WaitGroup waits for a collection of goroutines to finish.
Now let's see how the code above would look like when using the sync package
func main() {
wg := &sync.WaitGroup{}
for i := 0; i < 10; i++ {
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup) {
if t, ok := queryCache(id); ok {
fmt.Println("from cache")
fmt.Println(t)
}
wg.Done()
}(id, wg)
go func(id int, wg *sync.WaitGroup) {
if t, ok := queryDatabase(id); ok {
fmt.Println("from database")
fmt.Println(t)
}
wg.Done()
}(id, wg)
//time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
This code works fine, however this is a point where we still do not have all the coordination that we want, and we are not going to really be able to address this issue well until we talk about channels.
But what is happening here is we have got a task swap that is happening with the Go runtime. So it writes out from database and then it jumps over to another Go routine that starts writing and prints out its book.
So in the picture below we can see that we have two problems. Once the "from database" appears multiple times and then it does not.
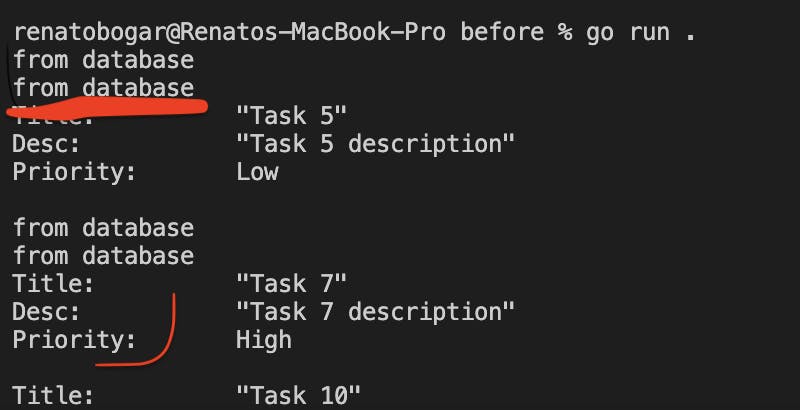
So in this case we have got multiple goroutines that are accessing the Println function from the fmt package, which is not safe to access that concurrently.
So what was the code above good for ? It showed us that WaitGroup allows us to have our main function wait until all of the concurrent tasks are completed, before it returns.
Mutexes
So to continue we have to talk about Mutexes. If you delete the comment from the queryDatabase() function, you can run into many errors, and the code is still not working as expected.
func queryDatabase(id int) (Task, bool) { time.Sleep(300 * time.Millisecond) for _, t := range tasks { if t.ID == id { cache[id] = t return t, true } }
return Task{}, false
}
The second challenge that we have when working concurrently in our Go application is how to manage shared memory and that is the Mutex will help us to solve. Luckily we have some tooling for this in Go. If you write the command
go run --race .
You can see the following error message
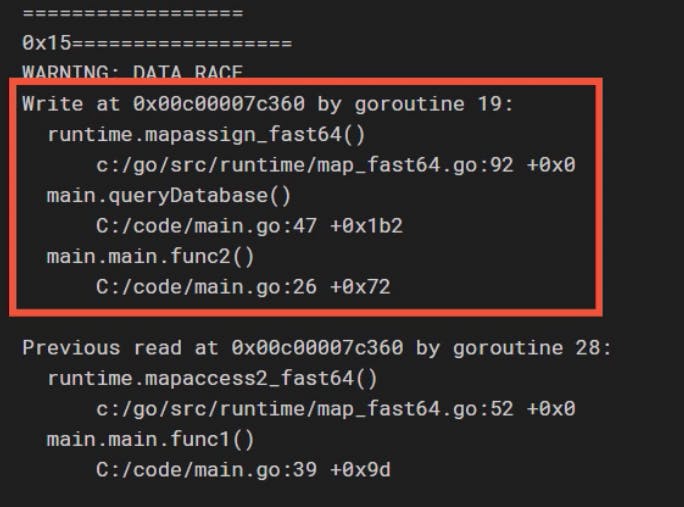 Which means in this case (where we are making ten different goroutines) we got a massive error message in the terminal.
Mutex (mutual exclusion lock) can be used to protect a portion of your code so that only one task or only. The owner of the mutex lock can access that code. So what we can use that for is to protect memory access.
We can lock the mutex, access the memory, and then unlock the mutex, ensuring that only one task can access that code at one time. Lets see the solution in code
Which means in this case (where we are making ten different goroutines) we got a massive error message in the terminal.
Mutex (mutual exclusion lock) can be used to protect a portion of your code so that only one task or only. The owner of the mutex lock can access that code. So what we can use that for is to protect memory access.
We can lock the mutex, access the memory, and then unlock the mutex, ensuring that only one task can access that code at one time. Lets see the solution in code
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cache = map[int]Task{}
var rnd = rand.New(rand.NewSource(time.Now().UnixNano()))
func main() {
wg := &sync.WaitGroup{}
m := &sync.Mutex{}
for i := 0; i < 10; i++ {
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup, m *sync.Mutex) {
if t, ok := queryCache(id, m); ok {
fmt.Println("from cache")
fmt.Println(t)
}
wg.Done()
}(id, wg, m)
go func(id int, wg *sync.WaitGroup, m *sync.Mutex) {
if t, ok := queryDatabase(id, m); ok {
fmt.Println("from database")
fmt.Println(t)
}
wg.Done()
}(id, wg, m)
//time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
func queryCache(id int, m *sync.Mutex) (Task, bool) {
m.Lock()
t, ok := cache[id]
m.Unlock()
return t, ok
}
func queryDatabase(id int, m *sync.Mutex) (Task, bool) {
time.Sleep(300 * time.Millisecond)
for _, t := range tasks {
if t.ID == id {
m.Lock()
cache[id] = t
m.Unlock()
return t, true
}
}
return Task{}, false
}
Now there is a little bit of inefficiency in this code. In a real world application the chances are we would be hitting the cache many, many more times than we would update the cache. Only one task can either be reading or writing, but it does not make sense to protect the cache for multiple reads. I can have as many goroutines reading from the cache as I want, as long as I am not writing to the cache at the same time. So we do have another type of mutex that is going to be a better one to use in this case, and cases like this, and that is called RWMutex or Read/Write Mutex.
RWMutex or Read/Write Mutex.
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cache = map[int]Task{}
var rnd = rand.New(rand.NewSource(time.Now().UnixNano()))
func main() {
wg := &sync.WaitGroup{}
m := &sync.RWMutex{}
for i := 0; i < 10; i++ {
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex) {
if t, ok := queryCache(id, m); ok {
fmt.Println("from cache")
fmt.Println(t)
}
wg.Done()
}(id, wg, m)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex) {
if t, ok := queryDatabase(id, m); ok {
fmt.Println("from database")
fmt.Println(t)
}
wg.Done()
}(id, wg, m)
//time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
func queryCache(id int, m *sync.RWMutex) (Task, bool) {
m.RLock()
t, ok := cache[id]
m.RUnlock()
return t, ok
}
func queryDatabase(id int, m *sync.RWMutex) (Task, bool) {
time.Sleep(300 * time.Millisecond)
for _, t := range tasks {
if t.ID == id {
m.Lock()
cache[id] = t
m.Unlock()
return t, true
}
}
return Task{}, false
}
So what happens in the code above: it is allowing multiple readers to acquire that read lock, but when it starts to write to the memory, the mutex is going to clear out all of the readers, let them finish their operations, then it is going to let the writer come in, make its update and when the unlock method is called then it is going to open the mutex up and then it is going to allow multiple readers to access the protected memory again. So in cases like this, when we have many many more times the number of readers than writers, it makes sense to use RWMutex.
Channels
Earlier we talked about the sync package and we learned about how its member enable us to coordinate the activities between multiple goroutines. Channels are an another mechanism that we have available to us to coordinate the work between multiple goroutines. So in general, as applications become very large it can become difficult to manage memory when it is shared between multiple concurrent tasks. So earlier we talked about mutexes to protect those shared read/writes, however it can become very difficult when those mutexes and that shared memory is shared among multiple Goroutines that potentially are spread throughout your application. Instead we can use channels. Now channels work a little bit differently than mutexes. Mutexes protect a certain section of memory so that the only one operator can manipulate that memory at one time. With a channel what we are going to do is we are actually going to generate copies of that memory along in our application. So one side of the channel we will have a sender that is going to send a message into the channel and then that is going to be received on the other side by another Goroutine, but the received message is going to be a copy of the original, not the original message itself. So we are no longer sharing the memory.
So if we point back in this article, when we did the concurrency discussion we talked about how there are two basic challenges. Coordinating tasks and shared memory. While WaitGroups help us with coordinating tasks, and mutexes help with shared memory, channels actually both of these use cases.
So lets talk about how do they do that.
The basic challenge that we hae that we are going to use channels for is illustrated right here in the picture below.
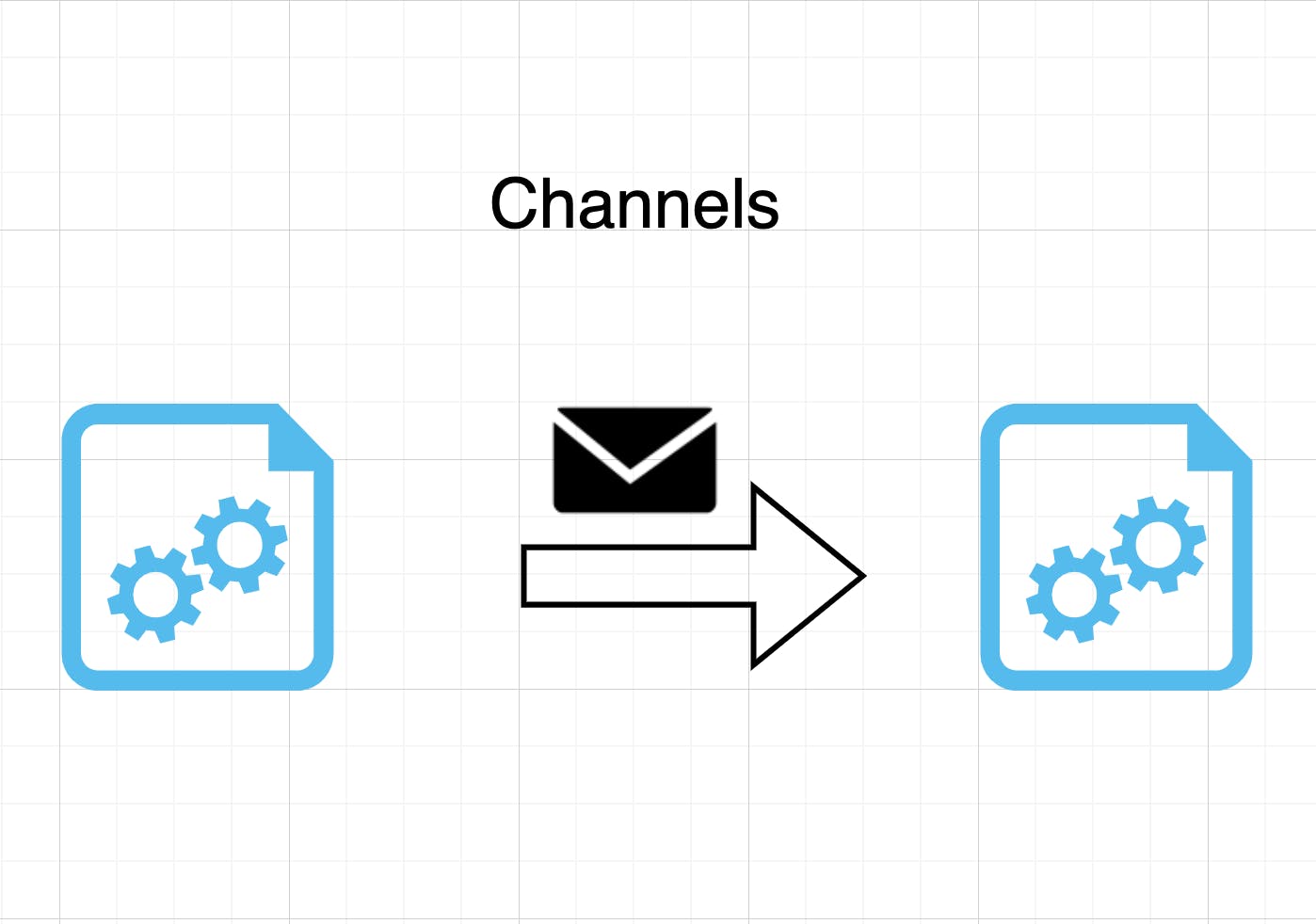
So we have got two Goroutines that are going about their business. But for some reason the goroutine on the left must send a message to the Goroutine on the right. How would we do that? Now we can use shared memory, and that would be handled by mutexes like we talked about in the last heading. But this can be handled by channels too.
So when we talk about a channel. What is going to happen is the Goroutine on the left side is not going to try and send the message directly to the Goroutine on the right, like we would do with a shared memory where we would have a mutex that would lock the shared memory.
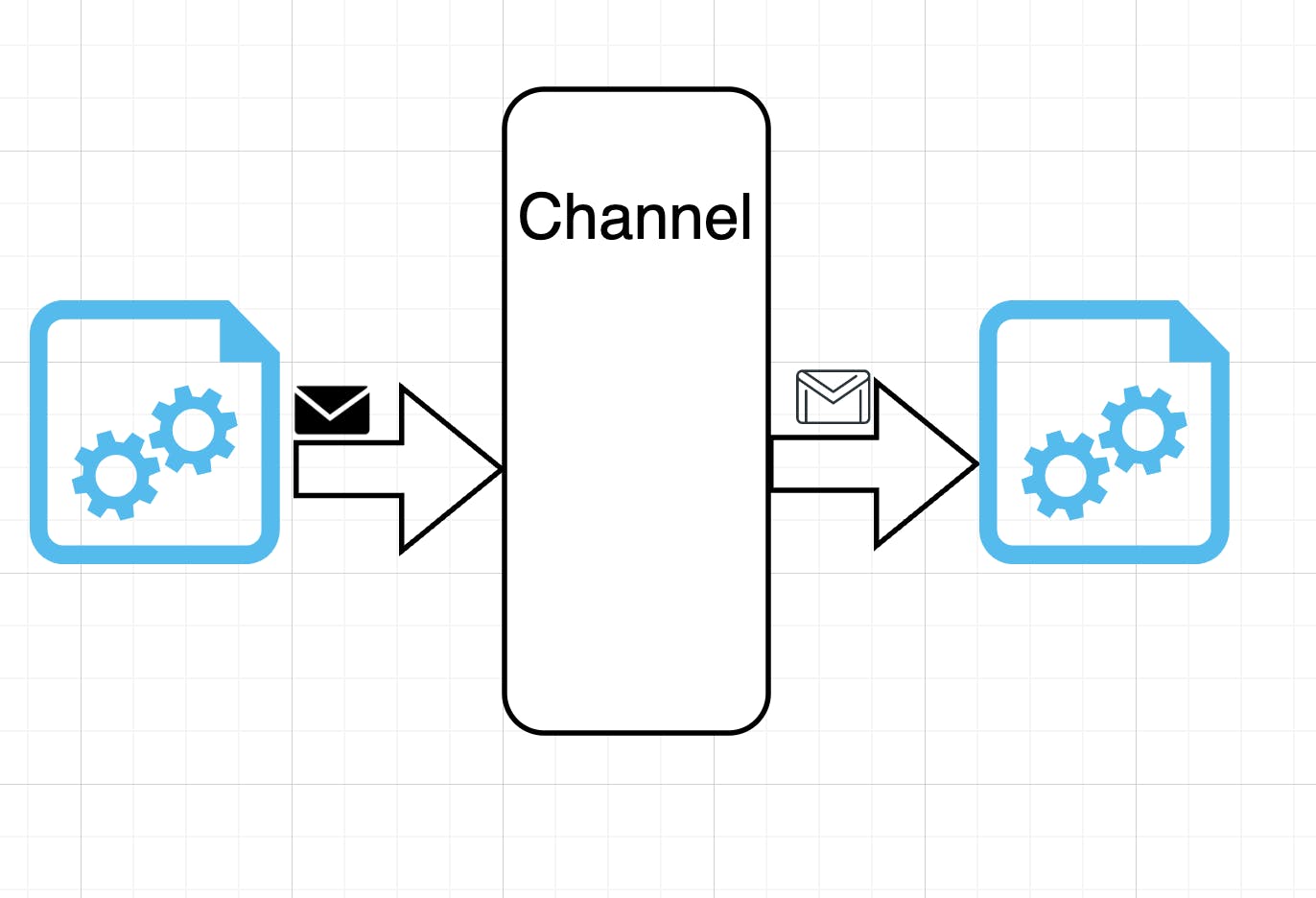
Instead we are going to send a message directly into the channel. The channel is going to send the copy of this message on to the receiving Goroutine. So the coordination of the communication is no longer the responsibility of the Goroutines. They do not have to worry about managing mutexes, locking and unlocking, should it be a read lock, should it be a write lock, they do not have to worry about any of that. The sender just passes a message into the channel, the receiver just receives a message from the chanel, they do not have to know about each other at all, they only have to know about the channel. So while the concept of channels is fairly simple, there is actually quite a bit involved in working with them.
Creating Channels
When it comes time to create a channel in your application, it is a relatively simple operation. You have probably used the build-in make function to make things like maps and slices. So creating a basic channel looks like this
ch := make(chan int)
So you have to use the make function and then you need to pass that the channel is going to be working with. And then following the chan keyword is the type of message you are going to be sending and receiving with that channel. Channels, like almost everything else in Go, are strongly typed. So you do have to specify the type of message that that channel is going to be working with. In this case we are making a channel that is going to be able to send and receive integers. If you want to create a buffer channel, then all you need to do is provide a second argument to the function
ch := make(chan int, 5)
So in this case we are making a channel that is going to send and receive integers, but it has got an internal capacity of five. This means it can store five messages inside of that channel, without having any receivers immediately.
Unbuffered channels
So let's see an example of an unbuffered channel
func main() {
wg := &sync.WaitGroup{}
ch := make(chan int)
wg.Add(2)
go func (ch chan int, wg *sync.WaitGroup){
//receiving message from the channel
fmt.Println(<-ch)
wg.Done()
}(ch, wg)
go func (ch chan int, wg *sync.WaitGroup){
//sending message to the channel
ch <- 42
wg.Done()
}(ch, wg)
wg.Wait()
}
You can see that the
<-ch
Is pointing away from the channel - this means it is a reading. Then you can see the
ch <- 42
This means we are writing to the channel. Now if you run this code, you can see that it writes 42 to the terminal. However, you can also see that the two Goroutines do not know about each other at all. These two Goroutines are completely decoupled from one another. They are only in connection with the channel. So the code above works, but what happens if you have a situation where you need some capacity, you need to be able to decouple the sending and receiving of messages? Well in that case you can use a buffered channel.
Buffered Channels
Lets add one more line into the second Goroutine.
go func (ch chan int, wg *sync.WaitGroup){
//sending message to the channel
ch <- 42
ch <- 27
wg.Done()
}(ch, wg)
What happens if we run like this right away? In this case, if we try to run the application right now, we get a deadlock condition, because we are trying to write to a channel which does not have an active receiver.
So change the main function code to the following
func main() {
wg := &sync.WaitGroup{}
ch := make(chan int, 1)
wg.Add(2)
go func (ch chan int, wg *sync.WaitGroup){
//receiving message from the channel
fmt.Println(<-ch)
wg.Done()
}(ch, wg)
go func (ch chan int, wg *sync.WaitGroup){
//sending message to the channel
ch <- 42
ch <- 27
wg.Done()
}(ch, wg)
wg.Wait()
}
But let's say that we need to be able to work with this. We need to have some sort of internal buffer within the channel. In that case, all we need to do is to provide a second parameter as you can see
ch := make(chan int, 1)
In this case, we can have one message sitting within the channel, so we do not have to have perfect matches between senders and receivers. If you run this code now, you can see that we get the correct message 42. We dont get 27, because we put 27 into the channel, but we never recived a message back out. So we have lost this message, but at least the application is not blocking. So when are you going to use buffered channels? Well there are use cases for them. Generally, an unbuffered channel is going to be sufficient for you, but there are rare cases where a buffer is important to have within the chanel, and so these are available to you. Now that we know how to create buffered and unbuffered channels, lets talk about the different types of communication that we can have with our channels
Channel Types
Now when we are talking about channel types we are really talking about the way that those channels can send or receive messages. And there are three different types that we have available:
- Bidirectional channel - normally this is created once u create a channel (make() func)
- Send-only channel
- Receive-only channel
Syntax
ch := make(chan int) //created channels are always bidirectional
func myFunction(ch chan int) { ... } //bidirectional channel
func myFunction(ch chan<- int) { ... }. //send-only channel
func myFunction(ch <-chan int) { ... }. //receive-only channel
Closing channels
The next operation I would like to write about in connection with channels is closing them. There may come a time when you have created a channel, you sent some messages into it, and you no longer have messages to send. So the sending side of the channel can actually close that channel to let receivers know that there are no more messages are going to be forthcoming. And we are going to close our channels using the built-in close function. Now there is one thing. You cannot check the status of a channel to see if it is closed or not, though. If you have got a channel variable, there is no built-in inspection mechanism to determine if that channel is closed or not. If you try and send a new message into a closed channel, you will trigger a panic. So there is no way to know if it is closed, and if you try and send a message, you are going to panic you application. So you have to handle this thing in your code and make sure that all parts of your code, which would use this channel, be aware of it. However, if you receive messages from the channel, that is actually going to be okay. If you have a buffered channel, all the buffered messages are still going to be available. Otherwise, if you are working with an unbuffered channel or the buffer is empty, then you are going to receive the zero-value for that channel. We can also use the comma okay syntax when receiving a message from the channel to determine if that channel is closed or not. So while you can not proactively inspect a channel for its status, you can receive a message from that channel, and then check that second return parameter to see if that is true or false.
So if you run the code below it is okay, since we are only reading from the closed channel.
func main() {
wg := &sync.WaitGroup{}
ch := make(chan int, 1)
wg.Add(2)
go func (ch chan int, wg *sync.WaitGroup){
//receiving message from the channel
fmt.Println(<-ch)
close(ch)
fmt.Println(<-ch)
wg.Done()
}(ch, wg)
go func (ch chan int, wg *sync.WaitGroup){
//sending message to the channel
ch <- 42
wg.Done()
}(ch, wg)
wg.Wait()
}
So as you can see after printing out 42, the terminal prints 0 which signals that the channel is closed. In summary, if you send a message into a closed channel, bad things happen, your application is going to panic, but if try and receive a message from a closed channel, that is not a big deal, you will get the zero value. But we do need some way of detecting that. So lets continue with the control flows.
Control Flows
If statement
When it comes to working with channels there are three possibilities about how they interact with the control flow.
- If statements
- For loops
- Select statements - kind of like switch statements, but they are specifically designed to work with channels
So what happens if I want to take a different action based on if the channel is closed or not ? Because at the moment it is impossible for me to tell right now whether we received the 0 value or the channel is closed. Well similar to maps in Go where we have the same problem, where we are interrogating an object and we are not real sure if we got the 0 value or if we got a legitimate value, we can use the ,ok syntax here
func main() {
wg := &sync.WaitGroup{}
ch := make(chan int, 1)
wg.Add(2)
go func (ch <-chan int, wg *sync.WaitGroup){
if msg, ok := <-ch; ok {
fmt.Println(msg,ok)
}
//receiving message from the channel
wg.Done()
}(ch, wg)
go func (ch chan<- int, wg *sync.WaitGroup){
close(ch)
wg.Done()
}(ch, wg)
wg.Wait()
}
Now lets continue with the controls flows, with the for loops.
For loops
Okay, so now let's look at for loops. So far, we have only been able to pass one message into the channel, and receive one message back up. Now when we have a channel and we send messages to it, and then we would like to read the copy of it on the other side, we can not know how many messages does that channel contain currently. The following code solves this problem for us too.
func main() {
wg := &sync.WaitGroup{}
ch := make(chan int, 1)
wg.Add(2)
go func (ch <-chan int, wg *sync.WaitGroup){
for msg := range ch {
fmt.Println(msg)
}
//receiving message from the channel
wg.Done()
}(ch, wg)
go func (ch chan<- int, wg *sync.WaitGroup){
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
wg.Done()
}(ch, wg)
wg.Wait()
}
As you can see we are iterating through the range of the channel.
Select statements
Select statements are very similar to switch stamements in their syntax, and they perform a similar function, in that there are multiple cases that they are going to handle and then based on the state of the application, they are going to take one of those paths. So lets see the syntax in here
ch1 := make(chan int)
ch2 := make(chan string)
select {
case i := <-ch1:
...
case ch2 <- "hello":
...
default:
// use default case for non-blocking select
}
In select statements instead of checking for truthiness, checking against some condition like you would do in a switch statement, we are actually going to try and either send or receive from a channel So in this case, our first case statement is trying to receive a message from ch1 into the variable i, and the other case is going to try and send the string "hello" into the channel ch2. Now if one of those channels is available to act, so if we have a message on ch1, or if ch2 is waiting for a message, then that case will be taken. Now if both of those cases are available, then it is randomly decided which case is actually going to fire. There is no predetermined order. So unlike switch statements, where the first case that matches gets acted upon, in select statements there is no predetermined order if multiple cases can be acted upon at the same time. Now, another unique thing about a select statement is, written like this, this select statement will block until it can act on one of those cases. So if there is no message on ch1, and ch2 is not ready for a message, we are actually going to stop the execution of the current Goroutine right here, until we can either receive a message from ch1 or send a message on ch2, so the entire Go routine is going to stop here until we can meet one of those conditions. This is what called a blocking select statement. If you only want to operate on one of these cases, only if the application is ready right at this instant to honor that, then you can add a default case. The default case makes this a non-blocking select. So in case we do not have a message available on ch1, and ch2 is not able to receive a message, in that case neither of our cases can be honored, so we are going to execute the default case. This is called a non-blocking select, and your goroutine will not pause here. If one of those case statements can not be honored, it will simply execute the default case and continue executing. Now lets add this into our code and the problem we were facing with the double database string, and the no database string can be solved.
So the final code looks like this
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
var cache = map[int]Task{}
var rnd = rand.New(rand.NewSource(time.Now().UnixNano()))
func main() {
wg := &sync.WaitGroup{}
m := &sync.RWMutex{}
cacheCh := make(chan Task)
dbCh := make(chan Task)
for i := 0; i < 10; i++ {
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex, ch chan<- Task) {
if t, ok := queryCache(id, m); ok {
ch <- t
}
wg.Done()
}(id, wg, m, cacheCh)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex, ch chan<- Task) {
if t, ok := queryDatabase(id); ok {
m.Lock()
cache[id] = t
m.Unlock()
ch <- t
}
wg.Done()
}(id, wg, m, dbCh)
go func(cacheCh, dbCh <-chan Task) {
select {
case b := <-cacheCh:
fmt.Println("from cache")
fmt.Println(b)
<-dbCh
case b := <-dbCh:
fmt.Println("from database")
fmt.Println(b)
}
}(cacheCh, dbCh)
time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
func queryCache(id int, m *sync.RWMutex) (Task, bool) {
m.RLock()
t, ok := cache[id]
m.RUnlock()
return t, ok
}
func queryDatabase(id int) (Task, bool) {
time.Sleep(100 * time.Millisecond)
for _, t := range tasks {
if t.ID == id {
return t, true
}
}
return Task{}, false
}